[paper] E-BRANCHFORMER: BRANCHFORMER WITH ENHANCED MERGING FOR SPEECH RECOGNITION
E-Branchformer[Kim22]는 음성인식 분야 SOTA모델 Conformer와 견주어 비교되는 모델이다.
ASR 분야 여러가지 트랜스포머 변형 모델이 제안되었지만, CMU 대용량 음성모델 OWSM3.1 기본 구조로 사용되었다고 하여 공부를 결심하였다. (ICASSP2024 현장에서 OWSM3.1 세션을 감명 깊게 들었다.)
논문은 merging method, stacking additional point-wise module을 도입한 점에 기여를 하였다고 한다.
Summary
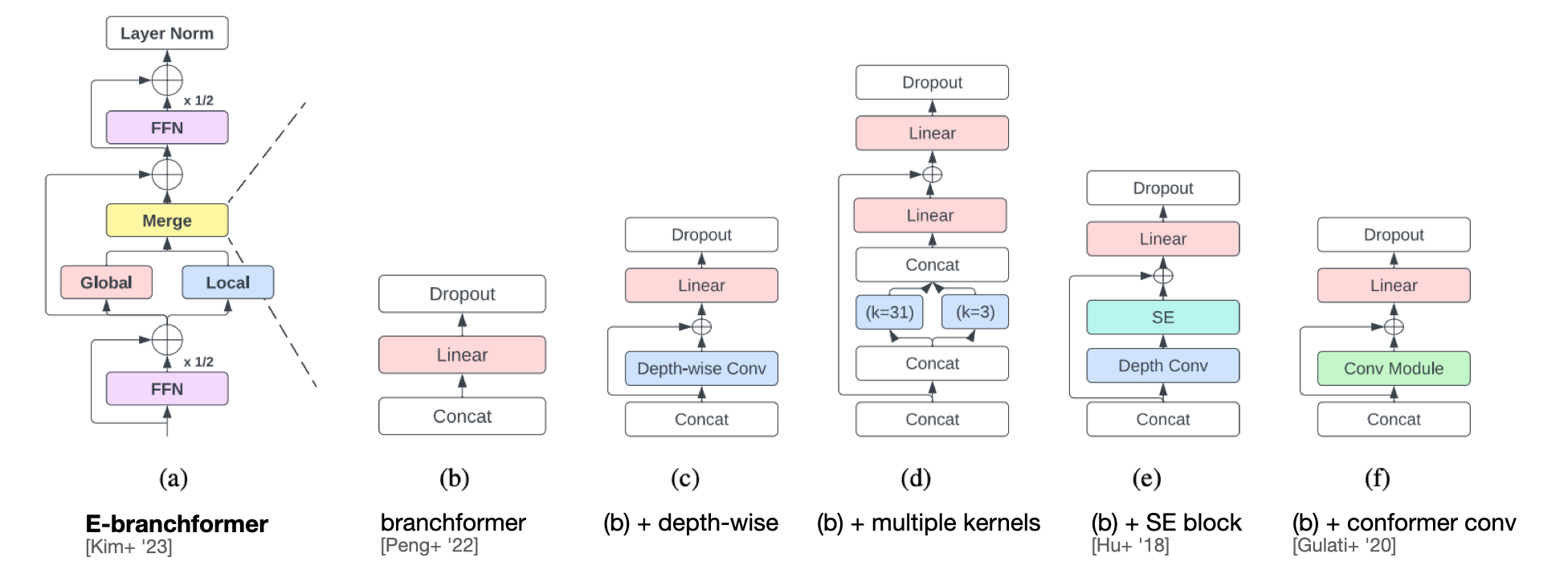
- Branchformer[Peng22]의 Conformer[Gulati20]와 차이점은 local, global branch를 parallel 하게 구조화한 점이다.
- Conformer의 sequential한 구조는 interpret, modify 하기 어려운 점이 있다.
- 어텐션과 컨볼루션의 위치가 고정되었지만(fixed), 꼬여있는(interleaving) 패턴을 가지는 것은 바람직하지 않다고 한다.
- 어텐션은 이차(quadratic) 배수의 복잡도를 보인다. w.r.t. the sequence length
- 이번 논문은 Branchformer[Peng22]의 merging module을 개선시킨 연구이다.
- Depth-wise 컨볼루션을 브랜치 병합에 활용하여 인접한 (adjacent) 특징을 반영하였다.
- SE block을 도입하여 브랜치 병합 중, global 정보를 반영하고자 하였다.
- AED 모델 성능이 뛰어나며, CTC, transducer는 차후 적용한다고 한다.
BRANCHFORMER
branchformer는 세 가지 구성이 포함된다. Attention (global)과 Local (cgMLP)를 concat 혹은 weighted average 방식으로 merge 시킨 아키텍쳐이다.
global extractor branch $Y_{G}$는 일반적인 트랜스포머 MHSA와 동일하다.
$Y_{G}=Dropout(MHSA(LN(X)))$
local extractor branch $Y_{L}$는 4가지 모듈로 이루어져있다. CSGU에 [Sakuma+ ‘21]가 인용되어 있어, 해당 논문에서 아이디어를 차용한듯 하다. (ICRL reject 당했지만, 음성 길이 관련된 아키텍처를 연구한 논문이라 읽어보는게 좋을듯 하다.)
LayerNorm, 6차원 특징 변환, GELU를 통과한 입력은 $dim$기준으로 특징 $A, B$ 두가지를 나눈다. 한가지 특징, 예를 들어 $A$에 LayerNorm과 Depthwise Conv를 통과시키고, 나머지 특징 $B$와 원소 곱셈을 해준다. $U$, $V$는 linear projection이다.
$(1) Z = GELU(LN(X)U)$
$(2) [A B] = Z$
$(3) \tilde{Z} = CSGU(Z) = A \odot DwConv(LN(B))$
$(4) Y_{L} = Dropout(\tilde{Z}V)$
espnet을 참고하니, 다음과 같이 코드가 작성되어 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def forward(self, x, gate_add=None):
"""Forward method
Args:
x (torch.Tensor): (N, T, D)
gate_add (torch.Tensor): (N, T, D/2)
Returns:
out (torch.Tensor): (N, T, D/2)
"""
x_r, x_g = x.chunk(2, dim=-1)
x_g = self.norm(x_g) # (N, T, D/2)
x_g = self.conv(x_g.transpose(1, 2)).transpose(1, 2) # 변환 후 다시 (N, T, D/2)로 만든다
if self.linear is not None:
x_g = self.linear(x_g)
if gate_add is not None:
x_g = x_g + gate_add
x_g = self.act(x_g) #act()는 nn.Identy()와 동일함
out = x_r * x_g # (N, T, D/2)
out = self.dropout(out)
return out
merge module은 간단하게 concat하고, linear $W$를 통과시킨다.
$Y_{Merge} = Concat(Y_{G}, Y_{L})W$
E-BRANCHFORMER
E-branchformer는 merging 모듈을 개선시켜, 시간(temporal) 정보를 더욱 반영하였다고 한다.
Depth-wise convolution
Depth-wise 컨볼루션은 인접한 특징 (adjacent feature)를 반영하면서, 연산량 혹은 속도의 큰 차이를 보이지 않는다.
기존 Branchformer는 linear projection을 통과하여 채널 기준으로 병합되지만(fused), depth-wise 컨볼루션을 활용하면 공간 정보를 보완할 수 있다.
$Y_{C} = Concat(Y_{G}, Y_{L})$
$Y_{D} = DwConv(Y_{C})$
$Y_{Merge} = (Y_{C} + Y_{D})W$
Squeeze-and-Excitation
SE-block은 global한 정보를 활용하는 모듈이다. 병합전, $\bar{Y}_{D}$ 에 SE-Block을 적용시켰다고 한다.
일반 SE block과의 차이점은 $Sigmoid$가 아닌 $Swish$ 활성함수를 사용했다는 점이다.
Point-wise FFN
Branchformer는 2개 cgMLP가 있지만, Transformer와 다르게 FFN은 사용하지 않는다. FFN은 시간 (temporal) 정보 aggregation 이후 개별적인 특징을 (pointwise) 정제하는 특징이 있다.
트랜스포머는 MSHA와 FFN을 스택으로 특징을 처리하며, interleaving 패턴으로 쌓아올리는데, [55]에 따르면 random하게 하는게 낫다고 한다.