[paper] Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
VITS는 One-stage TTS 중에서 준수한 natural sounding audio를 생성하는 모델이다.
2021년 ICML에 억셉되었으며, Glow-TTS, Hifi-GAN 등 좋은 평가를 받고 있는 모델 저자들이 함께 진행한 연구이다.
Abstract에 따르면, 본 연구는 variational inference augmented with normalizing flows and adversarial training process, 그리고 stochastic duration predictor 을 도입한 것이 주요 내용이라고 한다.
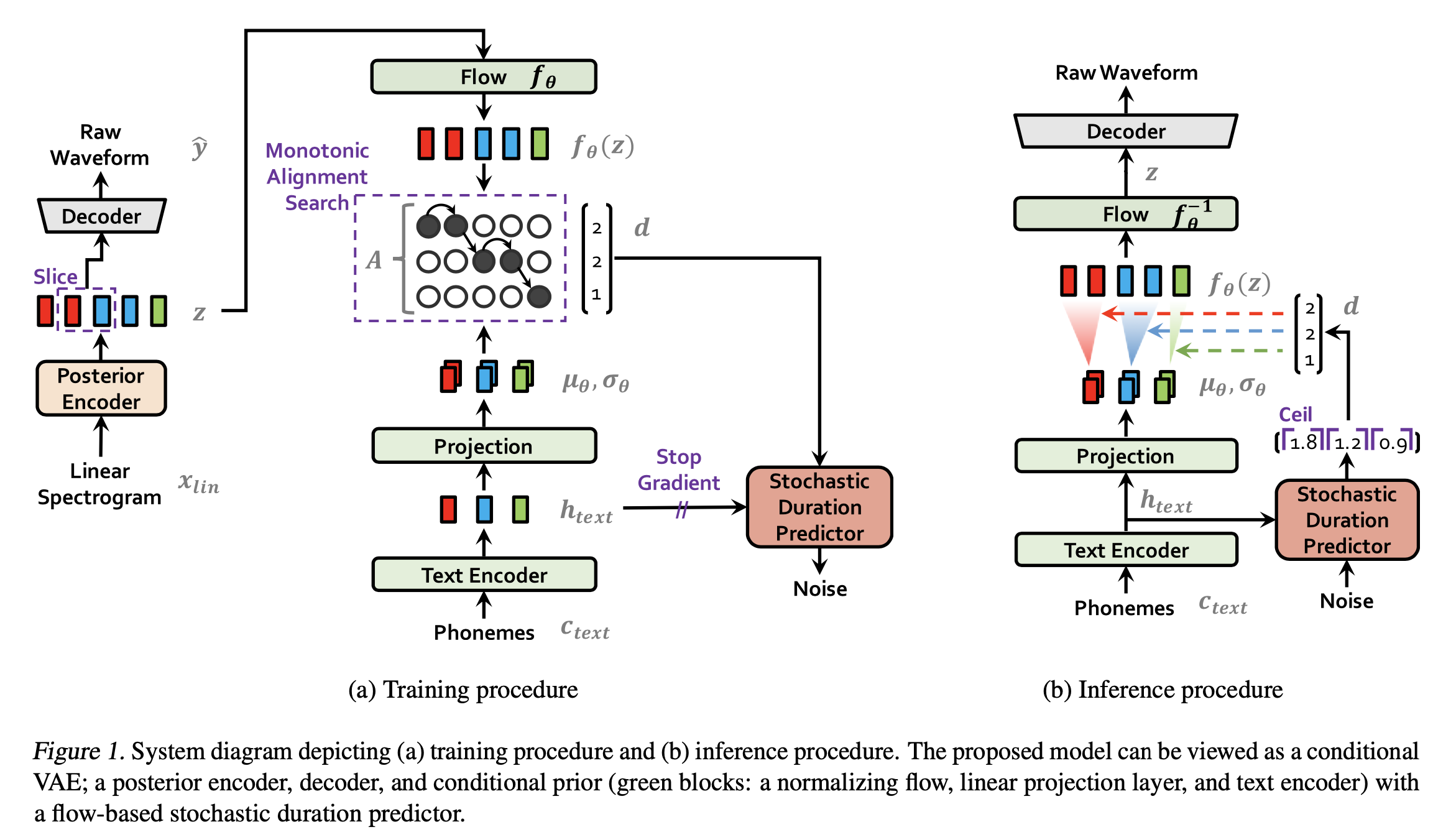
핵심 요약
- conditional VAE formulation
- ELBO 방법을 활용하여, Text $c$ 가 Speech $x$에 가까워질 수 있게 훈련시키는 것
- Reconstruction loss를 적용하여 Speech 입력과 출력의 차이를 줄이는 것
- KL 발산을 활용하여 Speech의 $z$와 Text의 $z$를 줄이는 것
- alignment estimation
- MAS 방법으로 text-speech 정렬
- SDP로 출력 speech 시간 결정
- adversarial training
- Least square loss로 GAN 훈련에 기여 (LSGAN)
- feature matching loss로 GAN 훈련에 기여
2.1.1
최대우도법은 가장 큰 우도가 그럴듯한 분포일 것이라 추측하는 것이다. maximizing the variational lower bound
복잡한 분포를 간단한 분포로 변환하는 것. distance measure
| 데이터 $\log_{p \Theta} (x | c)$ 의 lower bound를 찾는 것이다. |
given c, latent z $q_{\phi}(z|x)$는 사후확률 approximate posterior distribution이다.
loss는 negative ELBO, sum of reconstruction loss and KL divergence이다.
2.1.2
Latent z에 upsampling을 하고 $\hat{x}{mel}$ mel-spectrogram으로 변환한다. 이후 실제 $x{mel}$ 과의 차이를 reconstruction loss로 사용한다.
Laplace 분포를 고려했을 때, 이를 최대우도추정 으로 간주할 수 있다. Estimation은 훈련에만 해당된다.
훈련시, windowed generator training 기법을 사용한다고 한다. (일부만 훈련을 진행하는 것)
2.1.3
prior encoder $c$ 에는 $c_{text}$ 와 $A$ 가 있다. $A$ 는 hard monotonic attention matrix이다. $A$ 는 GT가 없기 때문에, 훈련 iteration 마다 estimate 해야 한다.
posterior encoder에 높은 화질 정보를 전달하기 위해, $x_{lin}$ linear-scale 스펙트로그렘을 사용한다고 한다. input이 달라도 variational inference가 가능하다고 한다.
factorized 정규분포는 prior, posterior 인코더를 파라미터로 나타내기 위해 필요하다.
normalizing flow $f_{\Theta}$ 를 적용하면 realistic sample을 만들 수 있다. 이는 rule of change-of-variables에 따라 simple 분포를 complex 분포로 변환하는 것이다. (invertible transformation) (가역행렬과 상관있는 것인가?)
2.2
2.2.1.
MAS는 Glow-TTS에서 제안된 우도를 최대화할 수 있는 alignment를 찾는 방법이다.
2.2.2.
입력 토큰 $d_{i}$를 계산하여 determiniistic duration predictor에 사용할 수 있지만, 일반적으로 발화속도가 매번 다른 특징은 반영이 되지 않는다. 따라서 stochastic duration predictor을 디자인하여, 음소의 duration distribution을 설정할 수 있다.
stochastic duration predictor은 최대우도법으로 훈련된 방법이다.
이산된 int 값이고, 스칼라 값이기에 variational dequantization, variational data augmentation 기법을 사용한다.
time resolution and dimension