[paper] Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions, ICASSP 2018
Tacotron2는 Google에서 제시한 Speech Synthesis 논문이다.
Recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize time-domain waveforms from those spectrograms.
RNN 모델을 활용하여, 텍스트를 멜스펙트로그램(음성특징)으로 매핑시켜준다. 이후, Wavenet을 보코더 (vocoder)로 사용하여 TTS를 구현한다. 이는 2 stage라고 볼 수 있다.
멜스펙트로그램의 mel-filter는 사람의 청각기관이 주파수를 linear하게 인식하지 않는 특징을 반영한 필터이다.
인간은 lower frequencies 구간의 변화를 더 민감하게 반응한다. (higher frequency: fricatives, noise burst)
적용 과정은 다른 음성 특징과 유사하다. 음성을 window로 나누어, short-time Fourier transforms을 적용하고, mel-filter를 적용하면 멜스펙트로그램이 만들어진다.
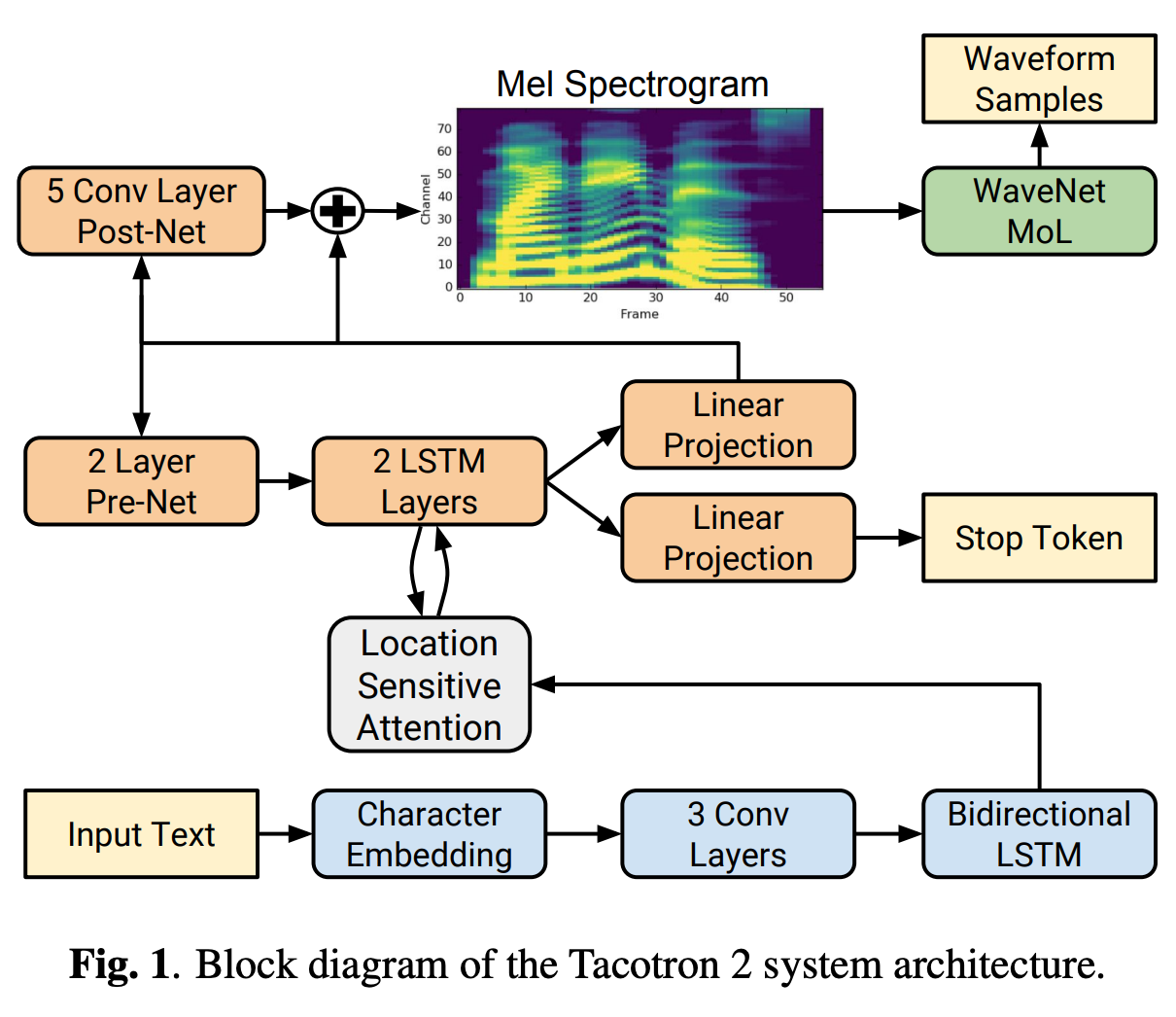
모델은 인코더, 디코더, 어텐션 구조로 구성되어 있다.
인코더는 3개의 CNN, 1개 BiLSTM의 구조이다.
CNN은 5*1 컨볼루션 필터를 사용하여 5개의 characters씩 담는(span) 역할을 하고, BiLSTM은 encoded features를 만드는 역할을 한다. BiLSTM을 도입한 이유는 full encoded sequence의 attention을 계산하기 위함임을 추측한다.
어텐션은 location-sensitive attention를 사용한다. 이는 additive attention에 cumulative attention weights를 사용한 기법이다.
디코더는 autoregressive RNN 구조를 갖는다. previous time steps는 pre-net (2개 linear layer)에 먼저 통과되고, 어텐션의 벡터와 연결(concat)하여 2개 LSTM에 전달된다. 이후 5개 CNN으로 구성된 post-net를 통과한 residual과 합쳐져 최종 값을 예측한다.
Post-net 전후는 mean-squared error (MSE)가 계산된다. 또한 Mixture Density Network의 log-likelihood loss를 시도했지만, 효과는 좋지 않았다.
stop-token은 sigmoid 함수로 언제 생성을 끝내야할지 결정하여, 길이를 조절할 수 있게 만든다. threshold 0.5를 통과하면 생성을 중단한다.
WaveNet은 멜스펙트로그램을 time-domain waveform으로 변환하는 별도의 모델이다.
-> 12.5ms frame hop을 처리하기 위해, 2 upsampling layers are used in the conditioning stack.
Maximum-likelihood training procedure, 혹은 teacher forcing 기법을 사용해서 좀 더 정확한 feature 예측을 할 수 있었다고 한다.